
if you could pick a standard format for a purpose what would it be and why?
e.g. flac for lossless audio because…
(yes you can add new categories)
summary:
- photos .jxl
- open domain image data .exr
- videos .av1
- lossless audio .flac
- lossy audio .opus
- subtitles srt/ass
- fonts .otf
- container mkv (doesnt contain .jxl)
- plain text utf-8 (many also say markup but disagree on the implementation)
- documents .odt
- archive files (this one is causing a bloodbath so i picked randomly) .tar.zst
- configuration files toml
- typesetting typst
- interchange format .ora
- models .gltf / .glb
- daw session files .dawproject
- otdr measurement results .xml
Open Document Standard (.odt) for all documents. In all public institutions (it’s already a NATO standard for documents).
Because the Microsoft Word ones (.doc, .docx) are unusable outside the Microsoft Office ecosystem. I feel outraged every time I need to edit .docx file because it breaks the layout easily. And some older .doc files cannot even work with Microsoft Word.
Actually, IMHO, there should be some better alternative to .odt as well. Something more out of a declarative/scripted fashion like LaTeX but still WYSIWYG. LaTeX (and XeTeX, for my use cases) is too messy for me to work with, especially when a package is Byzantine. And it can be non-reproducible if I share/reuse the same document somewhere else.
Something has to be made with document files.
It is unbelievable we do not have standard document format.
What’s messed up is that, technically, we do. Originally, OpenDocument was the ISO standard document format. But then, baffling everyone, Microsoft got the ISO to also have
.docxas an ISO standard. So now we have 2 competing document standards, the second of which is simply worse.
Bro, trying to give padding in Ms word, when you know… YOU KNOOOOW… they can convert to html. It drives me up the wall.
And don’t get me started on excel.
Kill em all, I say.
This is the kind of thing i think about all the time so i have a few.
- Archive files:
.tar.zst- Produces better compression ratios than the DEFLATE compression algorithm (used by
.zipandgzip/.gz) and does so faster. - By separating the jobs of archiving (
.tar), compressing (.zst), and (if you so choose) encrypting (.gpg),.tar.zstfollows the Unix philosophy of “Make each program do one thing well.”. .tar.xzis also very good and seems more popular (probably since it was released 6 years earlier in 2009), but, when tuned to it’s maximum compression level,.tar.zstcan achieve a compression ratio pretty close to LZMA (used by.tar.xzand.7z) and do it faster[1].zstd and xz trade blows in their compression ratio. Recompressing all packages to zstd with our options yields a total ~0.8% increase in package size on all of our packages combined, but the decompression time for all packages saw a ~1300% speedup.
- Produces better compression ratios than the DEFLATE compression algorithm (used by
- Image files:
JPEG XL/.jxl- “Why JPEG XL”
- Free and open format.
- Can handle lossy images, lossless images, images with transparency, images with layers, and animated images, giving it the potential of being a universal image format.
- Much better quality and compression efficiency than current lossy and lossless image formats (
.jpeg,.png,.gif). - Produces much smaller files for lossless images than AVIF[2]
- Supports much larger resolutions than AVIF’s 9-megapixel limit (important for lossless images).
- Supports up to 24-bit color depth, much more than AVIF’s 12-bit color depth limit (which, to be fair, is probably good enough).
- Videos (Codec):
AV1- Free and open format.
- Much more efficient than x264 (used by
.mp4) and VP9[3].
- Documents:
OpenDocument / ODF / .odt- @raubarno@lemmy.ml says it best here.
.odtis simply a better standard than.docx.
it’s already a NATO standard for documents Because the Microsoft Word ones (.doc, .docx) are unusable outside the Microsoft Office ecosystem. I feel outraged every time I need to edit .docx file because it breaks the layout easily. And some older .doc files cannot even work with Microsoft Word.
- @raubarno@lemmy.ml says it best here.
.taris pretty bad as it lacks in index, making it impossible to quickly seek around in the file. The compression on top adds another layer of complication. It might still work great as tape archiver, but for sending files around the Internet it is quite horrible. It’s really just getting dragged around for cargo cult reasons, not because it’s good at the job it is doing.In general I find the archive situation a little annoying, as archives are largely completely unnecessary, that’s what we have directories for. But directories don’t exist as far as HTML is concerned and only single files can be downloaded easily. So everything has to get packed and unpacked again, for absolutely no reason. It’s a job computers should handle transparently in the background, not an explicit user action.
Many file managers try to add support for
.zipand allow you to go into them like it is a folder, but that abstraction is always quite leaky and never as smooth as it should be.- By separating the jobs of archiving (
.tar), compressing (.zst), and (if you so choose) encrypting (.gpg),.tar.zstfollows the Unix philosophy of “Make each program do one thing well.”.
wait so does it do all of those things?
So there’s a tool called tar that creates an archive (a
.tarfile. Then theres a tool called zstd that can be used to compress files, including.tarfiles, which then becomes a.tar.zstfile. And then you can encrypt your.tar.zstfile using a tool called gpg, which would leave you with an encrypted, compressed.tar.zst.gpgarchive.Now, most people aren’t doing everything in the terminal, so the process for most people would be pretty much the same as creating a ZIP archive.
- By separating the jobs of archiving (
By separating the jobs of archiving (.tar), compressing (.zst), and (if you so choose) encrypting (.gpg), .tar.zst follows the Unix philosophy of “Make each program do one thing well.”.
The problem here being that GnuPG does nothing really well.
Videos (Codec): AV1
- Much more efficient than x264 (used by .mp4) and VP9[3].
AV1 is also much younger than H264 (AV1 is a specification, x264 is an implementation), and only recently have software-encoders become somewhat viable; a more apt comparison would have been AV1 to HEVC, though the latter is also somewhat old nowadays but still a competitive codec. Unfortunately currently there aren’t many options to use AV1 in a very meaningful way; you can encode your own media with it, but that’s about it; you can stream to YouTube, but YouTube will recode to another codec.
The problem here being that GnuPG does nothing really well.
Could you elaborate? I’ve never had any issues with gpg before and curious what people are having issues with.
Unfortunately currently there aren’t many options to use AV1 in a very meaningful way; you can encode your own media with it, but that’s about it; you can stream to YouTube, but YouTube will recode to another codec.
AV1 has almost full browser support (iirc) and companies like YouTube, Netflix, and Meta have started moving over to AV1 from VP9 (since AV1 is the successor to VP9). But you’re right, it’s still working on adoption, but this is moreso just my dreamworld than it is a prediction for future standardization.
Could you elaborate? I’ve never had any issues with gpg before and curious what people are having issues with.
This article and the blog post linked within it summarize it very well.
deleted by creator
I get better compression ratio with xz than zstd, both at highest. When building an Ubuntu squashFS
Zstd is way faster though
Damn didn’t realize that JXL was such a big deal. That whole JPEG recompression actually seems pretty damn cool as well. There was some noise about GNOME starting to make use of JXL in their ecosystem too…
wait im confusrd whats the differenc ebetween .tar.zst and .tar.xz
Different ways of compressing the initial
.tararchive.deleted by creator
I get your point. Since a
.tar.zstfile can be handled natively bytar, using.tzstinstead does make sense.Sounds like a Windows problem
deleted by creator
I get the frustration, but Windows is the one that strayed from convention/standard.
Also, i should’ve asked this earlier, but doesn’t Windows also only look at the characters following the last dot in the filename when determining the file type? If so, then this should be fine for Windows, since there’s only one canonical file extension at a time, right?
deleted by creator
There already are conventional abbreviations: see Section 2.1. I doubt they will be better supported by tools though.
deleted by creator
is av1 lossy
AV1 can do lossy video as well as lossless video.
- Archive files:
Ogg Opus for all lossy audio compression (mp3 needs to die)
7z or tar.zst for general purpose compression (zip and rar need to die)
The existence of zip, and especially rar files, actually hurts me. It’s slow, it’s insecure, and the compression is from the jurassic era. We can do better
why does zip and rar need to die
Zip has terrible compression ratio compared to modern formats, it’s also a mess of different partially incompatible implementations by different software, and also doesn’t enforce utf8 or any standard for that matter for filenames, leading to garbled names when extracting old files. Its encryption is vulnerable to a known-plaintext attack and its key-derivation function is very easy to brute force.
Rar is proprietary. That alone is reason enough not to use it. It’s also very slow.
How about tar.gz? How does gzip compare to zstd?
Both slower and worse at compression at all its levels.
why does ml3 need todie
It’s a 30 year old format, and large amounts of research and innovation in lossy audio compression have occurred since then. Opus can achieve better quality in like 40% the bitrate. Also, the format is, much like zip, a mess of partially broken implementations in the early days (although now everyone uses LAME so not as big of a deal). Its container/stream format is very messy too. Also no native tag format so it needs ID3 tags which don’t enforce any standardized text encoding.
(mp3 needs to die)
How are you going to recreate the MP3 audio artifacts that give a lot of music its originality, when encoding to OPUS? Past audio recordings cannot be fiddled with too much.
Also, fuck Zstandard, its a problematic format due to single file compression ability, hard to repair, not fully stable and lacking too many features compared to 7Z/RAR. Zst is also 15-20% worse at compression ratio. Its only a good format for temporary fast data transit applications (webpage/CDN serving, quick temporary database backups).
JPEG-XL for rasterized images.
I agree.
I especially love that it addresses the biggest pitfall of the typical “fancy new format does things better than the one we’re already using” transition, in that it’s specifically engineered to make migration easier, by allowing a lossless conversion from the dominant format.
Never heard of that, thanks for bringing it to my attention!
deleted by creator
GNOME introduced its support in version 45, AFAIK there isn’t a stable distro release yet that ships it.
Unfortunately, adoption has been slow and Alliance for Open Media are pushing back somewhat (especially Google[1], who leads the group) in favor of their inferior
.avifformat.
How does it compare to AVIF?
AVIF is slower, has a way smaller maximum resolution and doesn’t support progressive decoding as well as lossless JPEG recompression.
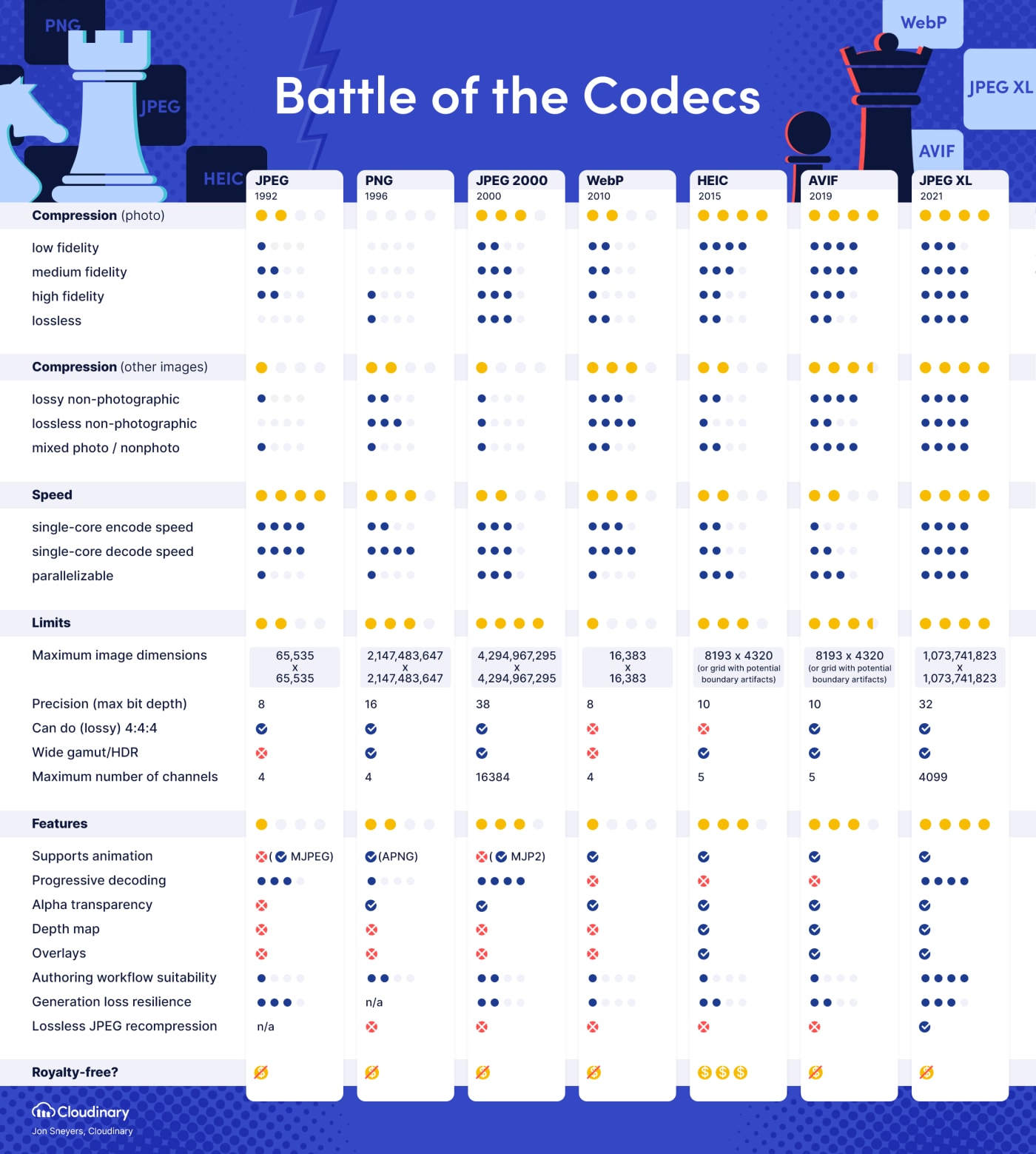
Oh dam, that resolution limit is a total deal breaker. Can’t believe anyone would release a format with those limitations today…
Literally any file format except PDF for documents that need to be edited. Fuck Adobe and fuck Acrobat
XML for machine-readable data because I live to cause chaosEither markdown or Org for human-readable text-only documents. MS Office formats and the way they are handled have been a mess since the 2007 -x versions were introduced, and those and Open Document formats are way too bloated for when you only want to share a presentable text file.
While we’re at it, standardize the fucking markdown syntax! I still have nightmares about Reddit’s degenerate four-space-indent code blocks.
I’d like an update to the epub ebook format that leverages zstd compression and jpeg-xl. You’d see much better decompression performance (especially for very large books,) smaller file sizes and/or better image quality. I’ve been toying with the idea of implementing this as a .zpub book format and plugin for KOReader but haven’t written any code for it yet.
I’d setup a working group to invent something new. Many of our current formats are stuck in the past, e.g. PDF or ODF are still emulating paper, even so everybody keeps reading them on a screen. What I want to see is a standard document format that is build for the modern day Internet, with editing and publishing in mind. HTML ain’t it, as that can’t handle editing well or long form documents, EPUB isn’t supported by browsers, Markdown lacks a lot of features, etc. And than you have things like Google Docs, which are Internet aware, editable, shareable, but also completely proprietary and lock you into the Google ecosystem.
JPEG XL for images because it compresses better than JPEG, PNG and WEBP most of the time.
XZ because it theoretically offers the highest compression ratio in most circumstances, and long decompression time isn’t really an issue when the alternative is downloading a larger file over a slow connection.
Config files stored as serialized data structures instead of in plain text. This speeds up read times and removes the possibility of syntax or type errors. Also, fuck JSON.
I wish there were a good format for typesetting. Docx is closed and inflexible. LaTeX is unreadable, inefficient to type and hard to learn due to the inconsistencies that arise from its reliance on third-party packages and its lack of guidelines for their design.
TOML for configuration files
100% this. Much more readable than JSON, YAML or other custom formats.
Markdown for all rich text that doesn’t need super fancy shit like latex
deleted by creator
I’d argue asciidoc is better, but less well known
Definitely FLAC for audio because it’s lossless, if you record from a high fidelity source…
exFAT for external hard drives and SD cards because both Windows and Mac can read and write to it as well as Linux. And you don’t have the permission pain…
What permission pain?
If you were to format the drive with extra and then copy something to it from Linux - if you try open it on another Linux machine (eg you distro hop after this event) it won’t open the file because your aren’t the owner.
Then you have to jump though hoops trying to make yourself the owner just so you can open your own file.
I learnt this the hard way so I just use exFAT and it all works.
i’d like there to be a way to standardise midi info in plugins for music
.dontuse for snaps
OTDR measurement results in like XML or whatever open self documenting format, just not SOR. Or even just in actual standards compliant SOR, if that’s all I can get.
i dont understand any if the acrobyms
except XML xD
OTDR: Optical Time Domain Reflectometry
SOR: Standard OTDR Record
XML: Extensible Markup Language.sor files are a mess, poorly standardized, too restrictive as a format, and every manufacturer makes their own proprietary extensions.
what file extension, what category
Category: OTDR measurement results
File extension: .xml or something entirely newwhat on earth does rhat do
An OTDR sends pulses of laser light into a fiber optic cable and records the minute reflections that occur at every point of the cable over time. The time of arrival of the reflections corresponds to the position of where it was reflected. This way you can record the attenuation of an entire cable just from shining in pulses from one end. Good for checking if a new cable was properly installed, or for finding the location of issues in existing cables for debugging.










