
Can’t wait to find hallucinated data in your uncompressed files.
The basic idea behind the researchers’ data compression algorithm is that if an LLM knows what a user will be writing, it does not need to transmit any data, but can simply generate what the user wants them to transmit on the other end
Great… but if that’s the case, maybe the user should reconsider the usefulness of transmitting that data in the first place.
I tried reading the paper. There is a free preprint version on arxiv. This page (from the article linked by OP) also links the code they used and the data they tried compressing, in the end.
While most of the theory is above my head, the basic intuition is that compression improves if you have some level of “understanding” or higher-level context of the data you are compressing. And LLMs are generally better at doing that than numeric algorithms.
As an example if you recognize a sequence of letters as the first chapter of the book Moby-Dick you’ll probably transmit that information more efficiently than a compression algorithm. “The first chapter of Moby-Dick”; there … I just did it.
I found the article to be rather confusing.
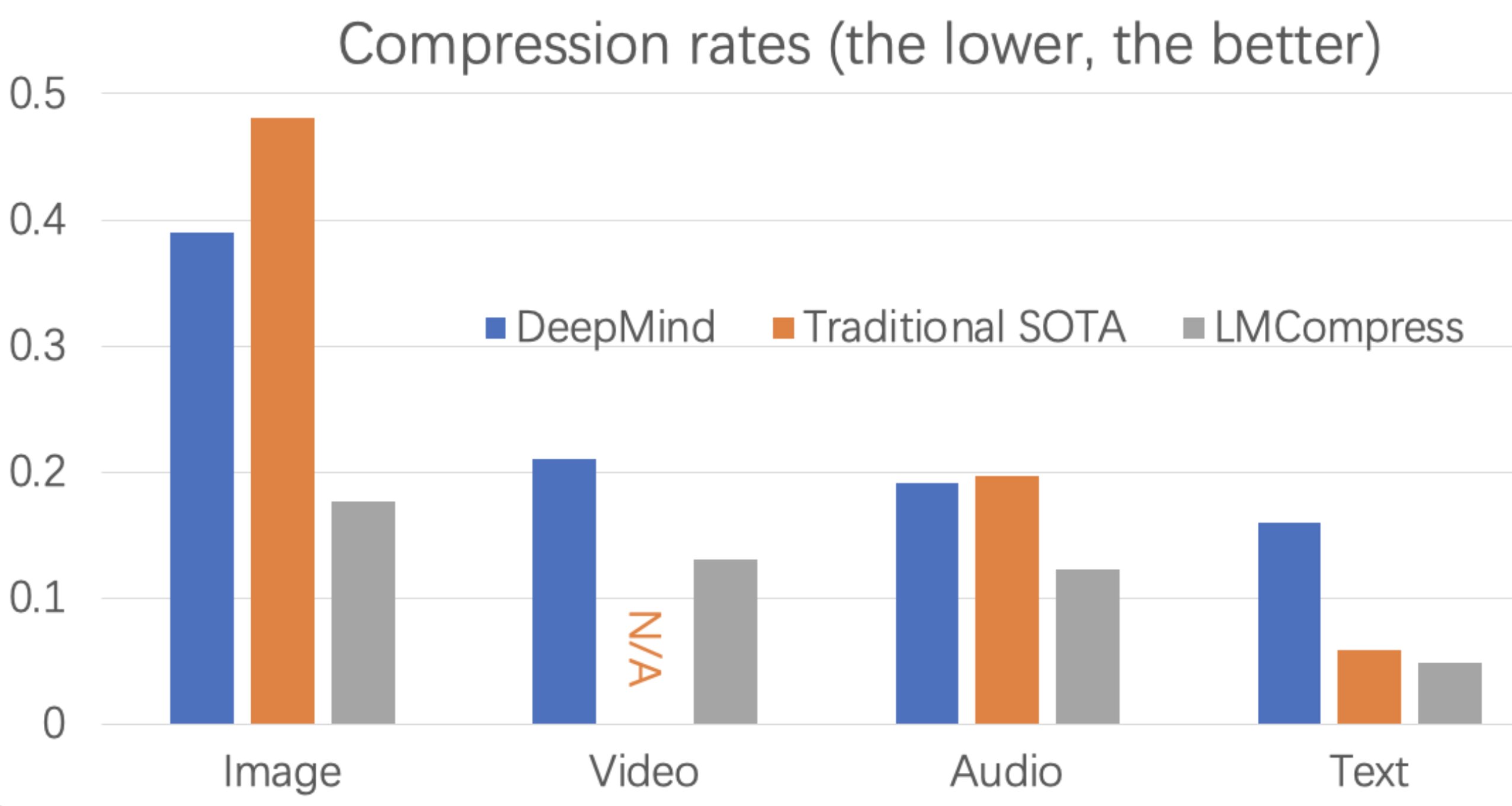
One thing to point out is that the video codec used in this research (but for which results weren’t published for some reason), H264, is not at all state of the art.
H265 is far newer and they are already working on H266. There are also other much higher quality codecs such as AV1. For what it’s worth, they do reference H265, but I don’t have access to the source research paper, so it’s difficult to say what they are comparing against.
The performance relative to FLAC is interesting though.
I wonder what the practical reasons for starting with h.264 are.
So if I have two machines running the same local LLM and I pass a prompt between them, I’ve achieved data compression by transmitting the prompt rather than the LLM’s expected response to the prompt? That’s what I’m understanding from the article.
Neat idea, but what if you want to transmit some information that an LLM can’t tokenize and generate accurately?
Ok so the article is very vague about what’s actually done. But as I understand it the “understood content” is transmitted and the original data reconstructed from that.
If that’s the case I’m highly skeptical about the “losslessness” or that the output is exactly the input.
But there are more things to consider like de-/compression speed and compatibility. I would guess it’s pretty hard to reconstruct data with a different LLM or even a newer version of the same one, so you have to make sure you decompress your data some years later with a compatible LLM.
And when it comes to speed I doubt it’s nearly as fast as using zlib (which is neither the fastest nor the best compressing…).
And all that for a high risk of bricked data.
I’m guessing that exactly the same LLM model is used (somehow) on both sides - using different models or different weights would not work at all.
An LLM is (at core) an algorithm that takes a bunch of text as input and produces an output of a list of word/probabilities such that the sum of all probabilities adds to 1.0. You could place a wrapper on this that creates a list of words by probability. A specific word can be identified by the index in the list, i.e. first word, tenth word etc.
(Technically the system uses ‘tokens’ which represent either whole words or parts of words, but that’s not important here).
A document can be compressed by feeding in each word in turn, creating the list in the LLM, and searching for the new word in the list. If the LLM is good, the output will be a stream of small integers. If the LLM is a perfect predictor, the next word will always be the top of the list, i.e. a 1. A bad prediction will be a relatively large number in the thousands or millions.
Streams of small numbers are very well (even optimally) compressed using extant technology.
Interesting how they forgot to go over the architecture for LMDecompress.
Middle-LLM compression
Removed by mod


